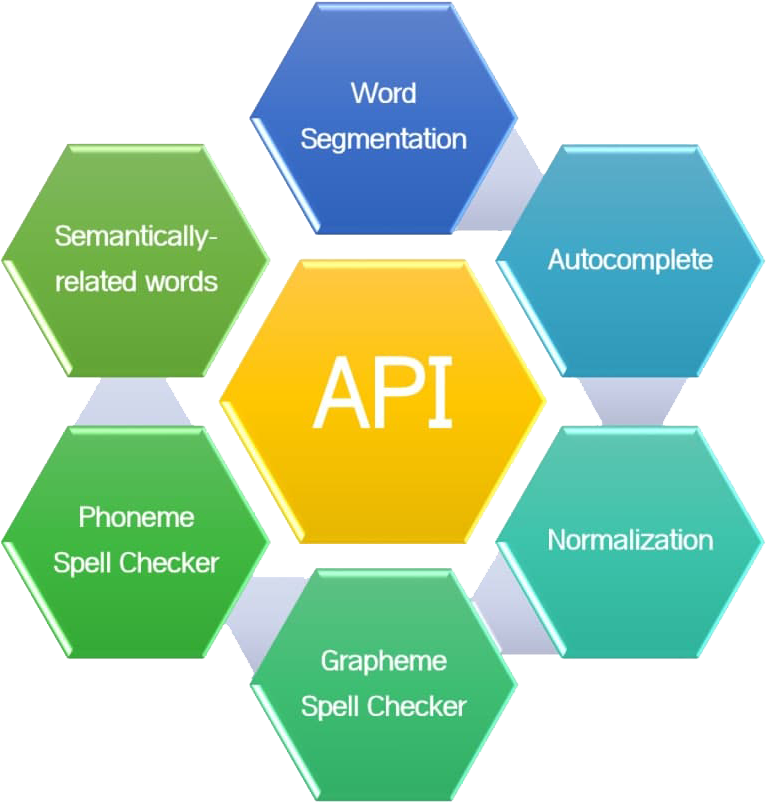
OUR API

Character Order Normalization
Some words such as “ស្រី្ត” can be multiple orders of characters. To ensure the consistent representation, words can be normalized by re-ordering the characters.
Spell Checking
There are two spell checkers – grapheme-based and phoneme-based. The grapheme-based spell checker searches for the suggestions within a pre-defined edit distance which is computed on graphemes. Similarly, the phoneme-based spell checker uses phonemes to compute edit distances when searching for the suggestions. The phoneme-based spell checker can identify different spelling realizations for the same word as in the case of “បម្លែង” and “បំលែង”.


Auto-completion
One of the useful features of Google search is the ability to auto-complete user query. The auto-completion API can auto-complete user query in Khmer in the same way.
Semantically-Related Words
Semantically-related words are not synonyms, but words with related meaning. Semantically-related words are words that are often in the same context. For example, “សំលៀកបំពាក់” is semantically related to “ខោ”, “អាវ”, “ខោអាវ”, “អាវធំ”, “ស្រោមជើង” and the likes.

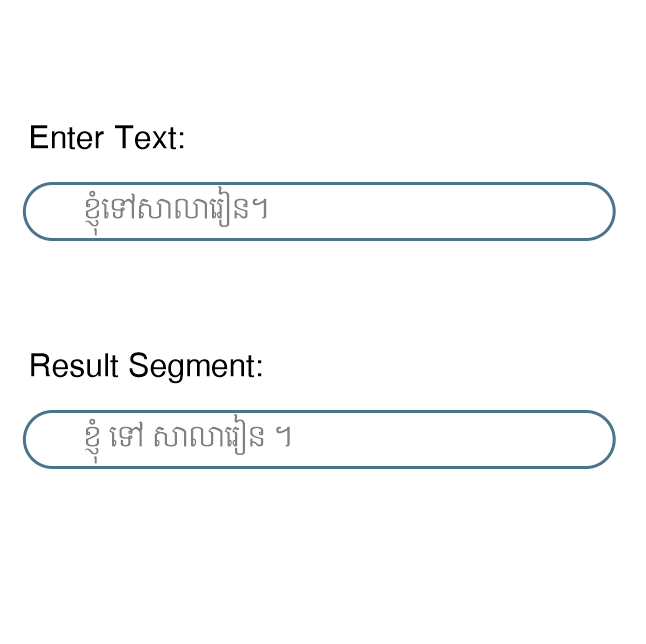
Word Segementation
In Khmer writing system, no explicit boundary delimiter is used. Therefore, word segmentation or, in broader term, tokenization is required to extract words for subsequent downstream tasks such search, text classification and so forth. The segmentation API uses the in-house segmentation algorithm to segment words in input text.
API DEMONSTRATION
PLEASE INPUT WORD HERE:
Please input WORD only
RESULT:
PLEASE INPUT TEXT HERE:
Please input text or sentences
RESULT:
CONTACT US FOR API
FEEDBACK AND CONTACT US FOR API
We love to hear from you about of API by giving us feedback via this form. Moreover, if you wish to use our API directly, please contact us via this form as well.+855 92 83 49 89
sovisal.chenda@techostartup.center
RUPP's Compound Russian Federation Blvd., Toul Kork, Phnom Penh, Cambodia